Proteins and their Structure
Levels of Protein Structure
The primary structures of proteins are quite sturdy. In general, fairly vigorous conditions are needed to hydrolyze peptide bonds. The enzyme pepsin, which aids in the hydrolysis of proteins, is found in the digestive juices of the stomach (Greek pepsis, meaning “digestion”). Papain, another enzyme that hydrolyzes protein (in fact, it is used in meat tenderizers), is isolated from papayas.
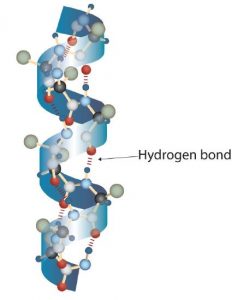
A protein molecule is not a random tangle of polypeptide chains. Instead, the chains are arranged in unique but specific 3D structures. The term secondary structure refers to the fixed arrangement of the polypeptide backbone. On the basis of X ray studies, Linus Pauling and Robert Corey postulated that certain proteins or portions of proteins twist into a spiral or a helix. This helix is stabilized by intrachain hydrogen bonding between two amino acids and is known as a right-handed α-helix. X ray data indicate that this helix makes one turn for every 3.6 amino acids, and the side chains of these amino acids project outward from the coiled backbone. The α-keratins, found in hair and wool, are exclusively α-helical in conformation. Some proteins have little or no helical structure, such as chymotrypsin, a digestive protein that breaks down other proteins. Others, such as hemoglobin, are helical in certain regions but not in others.
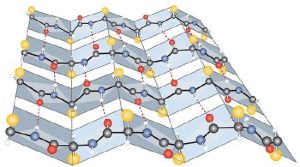
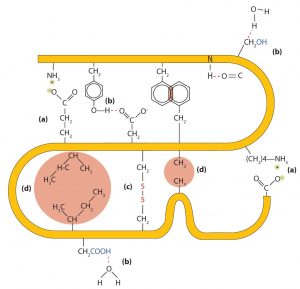
- Ionic bonding. Ionic bonds result from electrostatic attractions between positively and negatively charged side chains of amino acids. For example, the mutual attraction between a negative aspartic acid ion and a positive lysine ion helps to maintain a particular folded area of a protein (part (a) of the figure below).
- Hydrogen bonding. Hydrogen bonding forms between a highly electronegative oxygen atom or a nitrogen atom and a hydrogen atom attached to another oxygen atom or a nitrogen atom, such as those found in polar amino acid side chains. Hydrogen bonding (as well as ionic attractions) is extremely important in both the intra- and intermolecular interactions of proteins (part (b) of the figure below).
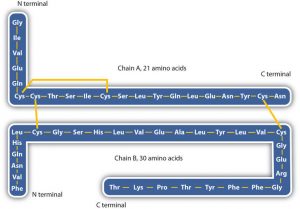
- Disulfide linkages. Two cysteine amino acid units may be brought close together as the protein molecule folds. Subsequent oxidation and linkage of the sulfur atoms in the two cysteine results in a disulfide linkage (part (c) of the figure below). Intrachain disulfide linkages are found in many proteins, including insulin (yellow bars in the structure of insulin above) and have a strong stabilizing effect on the tertiary structure.
- Dispersion forces. Dispersion forces arise when a normally nonpolar atom becomes momentarily polar due to an uneven distribution of electrons, leading to an instantaneous dipole that induces a shift of electrons in a neighboring nonpolar atom. Dispersion forces are weak but can be important when other types of interactions are either missing or minimal (part (d) of the figure below). This is the case with fibroin, the major protein in silk, in which a high proportion of amino acids in the protein have nonpolar side chains. Because nonpolar groups cannot engage in hydrogen bonding, the protein folds in such a way that these groups are buried in the interior part of the protein structure, minimizing their contact with water.
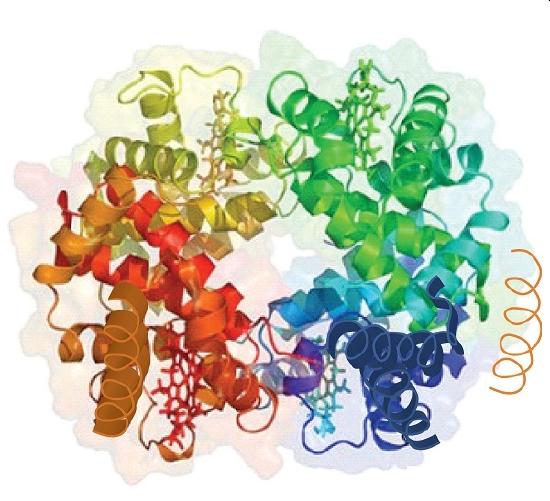
Source: Image from the RCSB PDB (www.pdb.org) of PDB ID 1I3D (R.D. Kidd, H.M. Baker, A.J. Mathews, T. Brittain, E.N. Baker (2001) Oligomerization and ligand binding in a homotetrameric hemoglobin: two high-resolution crystal structures of hemoglobin Bart’s (gamma(4)), a marker for alpha-thalassemia. Protein Sci. 1739–1749).
Summary of Levels of Protein Structure
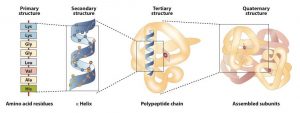
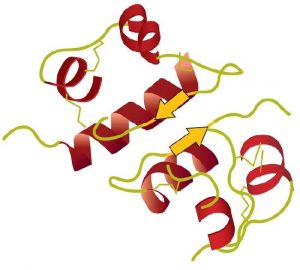
The primary structure consists of the specific amino acid sequence. The resulting peptide chain can twist into an α-helix or β-pleated sheet, which is one type of secondary structure. This helical segment is incorporated into the tertiary structure of the folded polypeptide chain. The single polypeptide chain is a subunit that constitutes the quaternary structure of a protein, such as hemoglobin that has four polypeptide chains.
Concept Review Exercises
- What is the predominant attractive force that stabilizes the formation of secondary structure in proteins?
- Distinguish between the tertiary and quaternary levels of protein structure.
- What name is given to the predominant secondary structure found in silk?
- What name is given to the predominant secondary structure found in wool protein?
Solutions
- hydrogen bonding
- Tertiary structure refers to the unique three-dimensional shape of a single polypeptide chain, while quaternary structure describes the interaction between multiple polypeptide chains for proteins that have more than one polypeptide chain.
- α-helix
- β-pleated sheet
Attributions
This page is based on “Chemistry 2e” by Paul Flowers, Klaus Theopold, Richard Langley, William R. Robinson, PhD, Openstax which is licensed under CC BY 4.0. Access for free at https://openstax.org/books/chemistry-2e/pages/1-introduction
This page is based on “The Basics of General, Organic, and Biological Chemistry” by David W Ball, John W Hill, Rhonda J Scott, Saylor which is licensed under CC BY-NC-SA 4.0. Access for free at http://saylordotorg.github.io/text_the-basics-of-general-organic-and-biological-chemistry/index.html
